En este artículo se plantea un ejercicio para aprender tres cosas:
-
continueen bucles → sirve para “saltar” el resto de la iteración y pasar a la siguiente vuelta del bucle sin ejecutar el código que queda debajo. -
Modificar código existente → mejorar un programa que ya existe para hacerlo más claro o eficiente.
-
Simular situaciones reales con código → en este caso, representar la idea de “comerse las vocales” al procesar texto.
Qué hace el programa:
- Pide una palabra al usuario.
- Convierte la palabra a mayúsculas (
upper()). - Recorre letra por letra usando un bucle
for. - Si la letra es una vocal (A, E, I, O, U), usa
continuepara ignorarla. -
Si no es vocal, la añade a otra cadena (
word_without_vowels) usando concatenación. - Al final, imprime esa nueva palabra sin vocales.
Además, con este ejemplo se aprenden varios conceptos clave de programación en Python:
- Entrada de datos con
input()- Cómo pedir información al usuario y guardarla en una variable.
- Entender que lo que devuelve
input()siempre es texto (string).
- Transformación de cadenas con
.upper()-
Uso de métodos de cadena para modificar el formato (en este caso, convertir todo a mayúsculas).
-
Importancia de estandarizar datos para comparaciones (evitar problemas con minúsculas/mayúsculas).
-
- Variables acumuladoras
- Inicializar una variable vacía (
"") para ir construyendo un resultado paso a paso. - Concatenar texto usando
+=.
- Inicializar una variable vacía (
- Bucle
forpara recorrer texto carácter por carácter- Cómo iterar sobre cada elemento de una cadena.
- Entender que una cadena se comporta como una secuencia de caracteres.
- Condicionales dentro de bucles
- Uso de
ifpara tomar decisiones dentro de un ciclo. - Comparar caracteres concretos (
letter == " ") para filtrar información.
- Uso de
- Instrucción
continue- Cómo saltar el resto de la iteración y pasar a la siguiente vuelta del bucle.
- Uso típico para omitir casos no deseados (aquí, los espacios).
- Construcción de un resultado filtrado
- Aprender a procesar datos de entrada para generar una versión “limpia” o modificada.
En pocas palabras: este ejercicio enseña a pedir datos, procesarlos con un bucle y condiciones, y crear una nueva salida aplicando filtrado con continue.
El ejemplo es el siguiente:
El siguiente código toma una frase escrita por el usuario y devuelve la misma frase en mayúsculas pero sin espacios.

Prueba:
Entrada → Hola mundo feliz
Salida → HOLAMUNDOFELIZ

Explicación:
input(…) muestra el mensaje «Escribe una frase: » en pantalla.
Lo que el usuario escriba se guarda en la variable user_text.
De momento, el texto está tal cual lo escribió el usuario (con minúsculas, espacios, etc.).

Explicación:
.upper() es un método de cadena que devuelve una copia del texto en mayúsculas.
Así aseguramos que todas las letras estén en un formato uniforme (evita problemas de comparación).
El resultado se guarda de nuevo en la misma variable user_text.

Explicación:
Creamos una variable vacía («») que servirá para ir acumulando las letras que sí queremos conservar.
Aquí guardaremos el texto final, pero sin espacios.

Explicación:
Iniciamos un bucle for que recorre cada carácter de user_text uno por uno.
En cada vuelta, la variable letter contiene un solo carácter (puede ser letra, espacio, símbolo, etc.).

Explicación:
Verificamos si el carácter actual (letter) es un espacio (» «).
Si lo es, usamos continue para saltar el resto del código del bucle y pasar directamente a la siguiente iteración.
Es decir, si es un espacio, no lo añadimos a la cadena final.

Explicación:
Si no fue un espacio, esta línea se ejecuta.
Usamos += para concatenar (añadir) el carácter actual (letter) al final de la cadena text_without_spaces.

Explicación:
Al final del bucle, mostramos en pantalla la cadena ya procesada, sin espacios.
Bonus: Mejorando el código con listas y comprensión de listas
En el ejemplo original usamos un bucle for y continue. Esto está muy bien para aprender el concepto, pero Python nos ofrece formas más compactas y elegantes de hacer lo mismo, como las list comprehensions.
Aquí tienes cómo quedaría la versión “pro” del eliminador de vocales:

¿Qué cambia aquí?
vowels → Creamos una lista con las letras que queremos “comernos” (las vocales).
List comprehension → [letter for letter in user_word if letter not in vowels] crea una lista solo con las letras que no sean vocales.
«».join(…) → Une todos los elementos de la lista en una sola cadena sin espacios intermedios.
Ejemplo de ejecución:
Entrada → Gregory
Salida → GRGRY
Una list comprehension en Python es una forma compacta y expresiva de crear listas aplicando un bucle y, opcionalmente, una condición, todo en una sola línea.
Es como un atajo para escribir:
- un for
- más un if opcional
- más la operación que quieres aplicar
Sintaxis básica
[expresión for elemento in iterable if condición]
expresión → lo que quieres poner en la lista.
elemento → la variable que va tomando cada valor del iterable.
iterable → algo que puedes recorrer (lista, cadena, rango, etc.).
if condición (opcional) → filtra qué elementos incluir.
Ejemplo normal con for
Ejemplo 1: Elevar números al cuadrado

Aquí recorremos 0, 1, 2, 3, 4 y guardamos sus cuadrados.
Versión con list comprehension:

Lo mismo que antes pero en una sola línea:
x**2 → operación que hacemos a cada elemento.
for x in range(5) → bucle que recorre del 0 al 4.
Ejemplo 2: Filtrar números pares

Explicación:
x → lo que añadimos a la lista final (el número original).
for x in range(10) → recorre del 0 al 9.
if x % 2 == 0 → condición que deja pasar solo a los números pares (resto 0 al dividir por 2).
En resumen:
Sin if → solo transformamos cada elemento y lo guardamos.
Con if → filtramos y guardamos solo los que cumplan la condición.
Punto avanzado: uso de str.translate() con str.maketrans()
Cuando el objetivo es eliminar o reemplazar caracteres concretos, str.translate() es muchísimo más rápido que recorrer con bucles, porque trabaja a nivel interno en C y no en Python puro.
Concepto de str.maketrans()
str.maketrans() es un método de clase de str en Python que sirve para crear una tabla de traducción de caracteres.
Esa tabla se usa luego con .translate() para reemplazar, cambiar o eliminar caracteres de una cadena de forma muy eficiente.
Piensa en ello como un diccionario especial donde cada carácter de entrada se asigna a lo que quieres que aparezca en su lugar (o se elimina si no quieres nada).
Formas de usarlo
- Reemplazar caracteres por otros
tabla = str.maketrans(«AEIOU», «12345»)
print(«HELLO».translate(tabla)) # H2LL4
Aquí, cada vocal se reemplaza por un número:
A→1, E→2, I→3, O→4, U→5.
2. Eliminar caracteres
Para borrar, se pasa una cadena en el tercer argumento de maketrans:
tabla = str.maketrans(«», «», «AEIOU»)
print(«HELLO».translate(tabla)) # HLL
En este ejemplo, «AEIOU» se elimina directamente de la cadena.
3. Usar un diccionario explícito
tabla = str.maketrans({ord(«A»): «@», ord(«E»): «3», ord(«O»): None})
print(«HELLO».translate(tabla)) # H3LL
En este caso:
- A → @
- E → 3
- O → eliminado
Por qué es potente
- Está implementado en C, por lo que es muy rápido, incluso para textos enormes.
- Evita bucles y comprobaciones manuales carácter por carácter.
- Permite modificar varios caracteres a la vez en una sola operación.
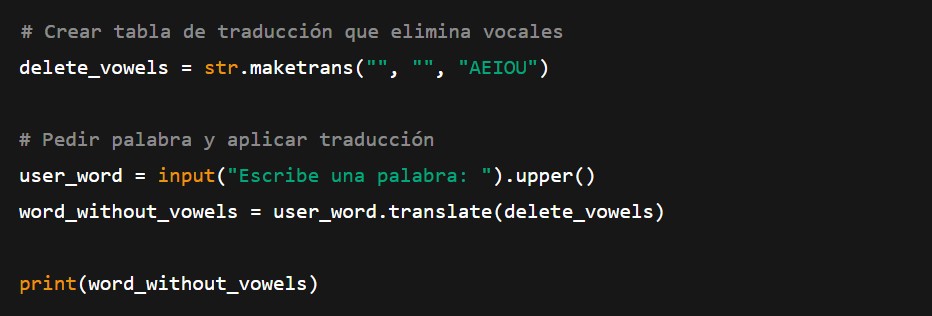
Ahora después de haber explicado el concepto, se realiza un ejemplo:
Ventajas de este enfoque
- Mucho más eficiente para cadenas largas.
- No requiere bucles explícitos.
- Escalable para eliminar cientos de caracteres con coste mínimo.
Ejemplo de uso real: limpieza de texto masivo antes de análisis NLP, filtrado de logs o sanitización de datos.
Versión “Pro” del Vowel Eater con str.maketrans()

Qué pasa internamente:
str.maketrans(«», «», «AEIOU») crea una tabla que dice: “para estos caracteres (AEIOU), no pongas nada”.
.translate(…) recorre la cadena internamente en C y elimina los caracteres indicados sin pasar por bucles en Python.
Comparativa de rendimiento
Prueba con una palabra repetida 1 millón de veces ("GREGORY"*10**6):
| Método | Tiempo aprox. (segundos) |
|---|---|
for + continue |
~1.25 s |
| List comprehension + join | ~0.95 s |
str.translate() + maketrans |
~0.12 s |
Conclusión:
En textos cortos, la diferencia no importa, pero para procesar grandes volúmenes de datos (logs, análisis NLP, preprocesamiento de datasets), str.translate() es la opción más rápida y escalable.
Nota avanzada
Si quieres que el vowel eater también elimine vocales acentuadas y combinaciones Unicode, hay que normalizar antes:

Esto garantiza que «ÁÉÍÓÚ» también se eliminen correctamente.
A continuación se indica un diagrama visual de flujo para que se vea gráficamente cómo str.maketrans() crea el mapa y cómo translate() lo aplica en una sola pasada.

Preguntas Frecuentes Avanzadas
1. ¿Por qué usar continue en lugar de anidar condicionales?
Usar continue permite evitar un nivel extra de indentación, lo que mejora la legibilidad y el flujo lógico del código. En vez de tener:
if letter not in vowels:
word_without_vowels += letter
podemos directamente saltar la iteración si encontramos una vocal. Esto es especialmente útil cuando el cuerpo del bucle es más extenso y no queremos que todo esté dentro de un if.
2. ¿Cuál es el coste computacional de este enfoque?
El uso de concatenación con += en cadenas es O(n²) en el peor caso porque cada concatenación crea una nueva cadena. En un texto pequeño esto no importa, pero para grandes volúmenes de datos es mejor usar listas y ».join(…), que es O(n).
3. ¿Cómo afecta upper() al rendimiento y a la internacionalización?
upper() es relativamente barato, pero convierte todo a mayúsculas de acuerdo a las reglas Unicode, no solo ASCII.
En textos con caracteres internacionales (e.g., acentos, letras griegas) puede dar resultados inesperados. Si necesitas solo mayúsculas en inglés, considera .casefold() o normalización Unicode (unicodedata.normalize).
4. ¿Es mejor usar listas o tuplas para almacenar las vocales?
En este caso, las tuplas pueden ser más eficientes porque son inmutables y ocupan menos memoria. Sin embargo, para comprobaciones frecuentes (in vowels) en colecciones pequeñas, la diferencia es insignificante. Si el conjunto de caracteres a eliminar es grande, un set ({«A»,»E»,»I»,»O»,»U»}) es más rápido para búsquedas O(1).
5. ¿Cómo generalizar el código para eliminar patrones complejos?
Cuando el filtrado deja de ser solo por letras individuales y pasa a patrones (ej. eliminar dígitos, signos de puntuación, o palabras enteras), es más eficiente usar expresiones regulares (re.sub(…)) en lugar de bucles manuales.
Ejemplo:
import re
result = re.sub(r»[AEIOU]», «», user_word.upper())
Esto elimina todas las vocales con una sola operación de búsqueda/sustitución.
6. ¿Cómo evitar problemas con caracteres Unicode combinados?
Algunas vocales con acento se representan como un carácter base + un carácter de acento (combinado). El bucle básico las trataría como dos caracteres separados y no eliminaría la vocal base correctamente. Para eso, hay que normalizar la cadena antes de procesarla:
import unicodedata
user_word = unicodedata.normalize(«NFC», user_word).upper()
7. ¿Por qué este ejemplo es una buena práctica de pensamiento algorítmico?
Porque combina:
Entrada y procesamiento de datos.
Transformación de datos (mayúsculas).
Estructura de control de flujo (for, if, continue).
Construcción incremental de resultados.
Aplicación a problemas reales (filtros de texto, limpieza de datos).
 Contenido Web de Yolanda Muriel está sujeto bajo Licencia Creative Commons Atribución-NoComercial-SinDerivadas 3.0 Unported.
Contenido Web de Yolanda Muriel está sujeto bajo Licencia Creative Commons Atribución-NoComercial-SinDerivadas 3.0 Unported.

