In recent years, machine learning—especially neural networks—has become increasingly important in designing pattern recognition systems. The availability of effective learning techniques has been a key factor in the success of applications such as continuous speech recognition and handwriting recognition.
Pattern recognition systems improve when they rely more on automatic learning instead of handcrafted rules. Advances in machine learning now allow models to learn directly from pixel images. The traditional modular systems can be replaced by a unified approach called Graph Transformer Networks, which trains all the modules together for better overall performance criterion.
Natural data is too complex to recognize accurately by hand-designed rules, so pattern recognition systems usually combine automatic learning with handcrafted features. The traditional systems rely heavily on manually created feature extractors, but this makes accuracy depend on the designer and must be redone for each new task.
The method of recognizing individual patterns have two main modules.
- Feature Extraction Module
- It takes the raw input (such as an image, audio signal, or text).
- It converts that raw data into a feature vector, a compact and informative representation.
- This step is usually hand‑crafted and requires expert knowledge.
- Trainable Classifier Module
- It receives the feature vector.
- It outputs class scores, meaning the probabilities or decisions about which class the input belongs to.
- This part is trainable and can learn from data.
Flow:
- Raw input
- Feature Extraction
- Feature Vector
- Trainable Classifier
- Class Scores
Over the past decade, several key developments have transformed the way feature extraction is approached in pattern recognition. Faster and more affordable computing hardware has made it possible to rely on numerical, data‑driven methods instead of manually crafted algorithms. At the same time, the availability of large datasets for widely studied problems—such as handwriting recognition—has allowed designers to depend more on real data rather than handcrafted features. Additionally, modern machine‑learning techniques are now able to process high‑dimensional inputs and learn complex decision functions when supplied with large training sets. These combined advances have significantly improved the performance of speech and handwriting recognition systems, many of which now use multilayer neural networks trained with backpropagation.
Learning from data
The text explains that one of the most effective approaches to automatic learning is gradient‑based methods, where a model learns a function that maps input patterns to outputs. Learning is guided by a loss function that measures the error between the model’s output and the correct label. Training consists of adjusting the model’s parameters to minimize this average error on a labeled training set. However, true performance is evaluated on a separate test set, since accuracy on the training data is not meaningful.
The gap between training (error rate) and test error (error rate) decreases as the number of training samples grows. Increasing model capacity reduces training error but enlarges the gap, creating a trade‑off. The best generalization is achieved by choosing an optimal capacity. This idea leads to structural risk minimization, where capacity is controlled through regularization to balance low training error with low expected test error.
Gradient based learning
Gradient‑based learning works by minimizing a smooth loss function through the computation of its gradient. Because the gradient indicates how small changes in the parameters affect the loss, learning algorithms can efficiently update parameters in the direction that reduces error. This principle underlies many modern learning methods. The simplest example is gradient descent, where parameters are repeatedly adjusted based on the gradient to gradually improve performance.
Stochastic gradient descent updates parameters using an approximate or noisy version of the gradient, often based on a single sample. Although this causes the parameters to fluctuate, the method converges faster than standard gradient descent and second‑order methods for large training sets. It has been studied since the 1960s, but significant practical successes appeared only in the mid‑1980s.
Gradient back propagation
Gradient‑based learning has been used since the 1950s, but its full potential for complex tasks became clear later thanks to three key developments: realizing that local minima are not a major practical problem, the introduction of the back‑propagation algorithm for computing gradients in multilayer networks, and the demonstration that back‑propagation can successfully train deep neural networks with sigmoidal units. These advances established back‑propagation as an effective method for solving challenging learning problems.
Local minima generally do not pose a practical problem for multilayer neural networks, possibly because large networks create extra dimensions that avoid bad regions in parameter space. Back‑propagation has become the most widely used learning algorithm in neural networks—and likely the most widely used learning algorithm overall.
Learning in Real handwriting recognition systems
Neural networks trained with gradient‑based methods achieve top performance on handwritten digit recognition. However, real handwriting recognition is harder because it requires separating characters from their neighbors. The standard approach is heuristic over‑segmentation, which generates many possible cuts, but this is difficult and labor‑intensive to label correctly. A better solution is to train systems at the word level so they can learn to minimize overall recognition errors without needing precise character segmentation.
A second solution to avoid explicit segmentation in handwriting recognition: instead of cutting characters, the recognizer is swept across every possible position in the input image and relies on its ability to detect centered characters. The sequence of outputs from this scan is then interpreted by a Graph Transformer Network (GTN), which uses linguistic constraints to choose the most likely reading. Although this method could be computationally expensive, using Convolutional Neural Networks makes it efficient enough to be practical.
Globally trainable systems
Practical pattern‑recognition systems are usually built from several separate modules, such as a field locator, a segmenter, a character recognizer, and a post‑processor. Each module processes the output of the previous one, often represented as a graph whose arcs store numerical information. Traditionally, these modules are trained independently—often on simplified or pre‑segmented data—and later assembled into a full system. After assembly, some parameters are manually fine‑tuned to improve overall performance. This approach, however, is tedious, time‑consuming, and typically leads to suboptimal results because each module is optimized in isolation rather than for the performance of the complete system.
A better strategy is to train the entire system jointly, optimizing a global error function that reflects the final task, such as reducing misclassification at the document level. If the system’s overall loss function can be made differentiable with respect to all trainable parameters, then gradient‑based methods can be used to find a local minimum of this global objective. This would eliminate the need for manual adjustments and produce a more coherent and effective end‑to‑end solution.
Although a full pattern‑recognition system may seem too complex to train end‑to‑end, it becomes feasible if the global loss function is differentiable. In that case, the entire system can be modeled as a feed‑forward network of differentiable modules. Each module must produce outputs that are continuous and differentiable with respect to both its parameters and its inputs. When this condition is met, a generalized form of back‑propagation can be applied to compute gradients efficiently for all modules. A system composed of successive modules—each represented as a function of its inputs and parameters—can propagate derivatives backward, allowing joint optimization of the whole system.
Computing gradients in modular systems involves Jacobian matrices, which contain all partial derivatives of a module’s outputs with respect to its inputs or parameters. In practice, these Jacobians often do not need to be computed explicitly; instead, their product with derivative vectors can be calculated directly, making the process more efficient. This backward propagation of derivatives is analogous to how hidden layers operate in standard multilayer neural networks, whose internal outputs are not directly observable.
When systems become more complex than a simple cascade of modules, expressing partial derivatives can become ambiguous, and more rigorous approaches—such as using Lagrange functions—may be required. Traditional multilayer neural networks are presented as a specific case of this general framework, where each module corresponds to either a matrix multiplication or a nonlinear activation. This reinforces the broader point that complex recognition systems can be trained using generalized forms of back‑propagation.
When a recognition system is represented using graphs, each module can act as a Graph Transformer that takes graphs as input and outputs new graphs. A network of such modules forms a Graph Transformer Network (GTN). The passage states that GTNs can be trained using gradient‑based learning to minimize a global loss function, even though graphs are discrete structures. Although this seems paradoxical, the text notes that this difficulty can be overcome, as later sections demonstrate.
Application to the AEC Sector and the Open BIM Environment
The main ideas presented in Gradient-Based Learning Applied to Document Recognition can be strategically extended to the Architecture, Engineering, and Construction (AEC) sector, particularly within Open BIM environments, where complex, multidisciplinary information must be managed efficiently.
Applying the principles of gradient-based learning to AEC workflows suggests a shift toward integrated, data-driven optimization. Instead of manually defining rigid rule-based validation systems or isolated analytical tools, machine learning models could learn directly from large BIM datasets. For example, models could be trained to detect design inconsistencies, predict constructability issues, classify building components, or optimize energy performance by minimizing a global performance metric across the entire project model.
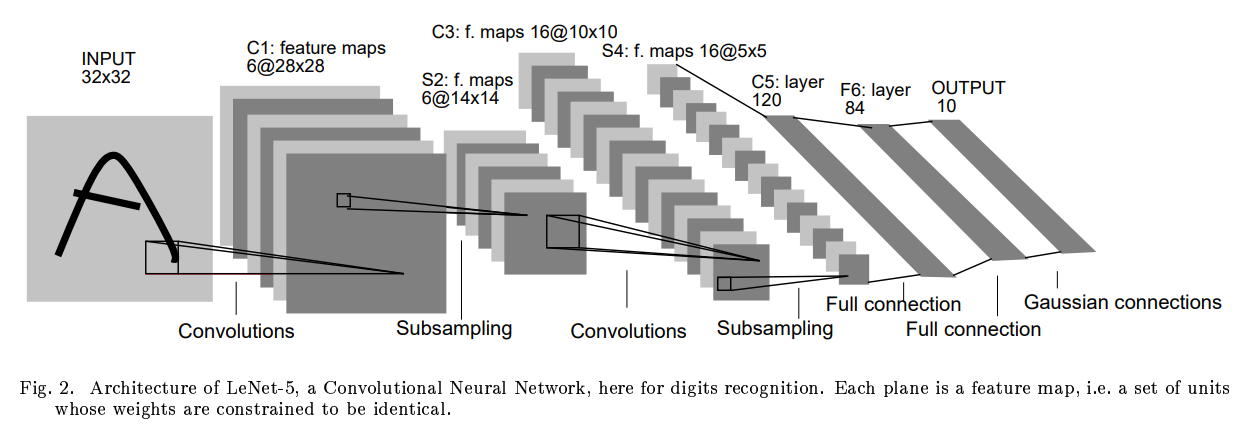
© Image. http://yann.lecun.com/
The following article paraphrases the main ideas presented in the introduction of the article «Gradient based learning applied to document recognition.» Autors: Yann LeCun, León Bottou, Yoshua Bengio and Patrick Haffner.
 @Yolanda Muriel
@Yolanda Muriel 
