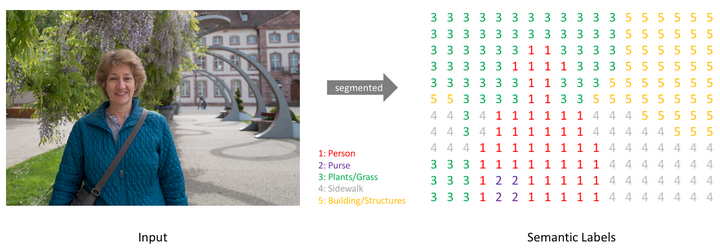
Semantic segmentation is a technique in computer vision where each pixel of an image is classified into a specific category. There is the input image, there is a transformation process, that allows the same image is represented as a grid of numbers, called semantic labels.
Each number in the grid corresponds to a class assigned to a pixel:
- 1 (red) : Person
- 2 (purple) : Purse
- 3 (green) : Plants/Grass
- 4 (gray) : Sidewalk
- 5 (yellow) : Buildings/Structures
Instead of showing colors and textures like the original image, the segmented output shows categorical labels, where every pixel is assigned a class. The system takes a normal image and classifies every pixel individually. This allows a computer to understand what each part of the image represents, not just detect objects. For example, it can distinguish between the person, the ground, vegetation, and buildings.
In short, The image demonstrates how a machine learning model converts a real-world image into a pixel-wise labeled map, enabling detailed scene understanding for applications like autonomous driving, robotics, and image analysis.
The diagram explains that instead of producing a single labeled image, a segmentation model internally represents the result as multiple 2D maps (one per class) stacked together into a 3D structure.
© Image. Jeremy Jordan
Output channel for each of the possible classes.
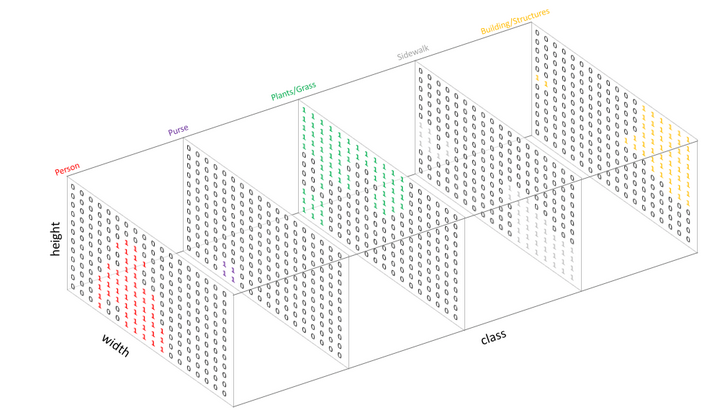
Spatial dimensions (input image)
- The base of the 3D blocks is defined by:
- Width
- Height
- These correspond to the pixel grid of the original image.
Class dimension (depth)
- The third axis is labeled “class”.
- Each slice (or layer) along this axis represents one specific category:
- Person (red)
- Purse (purple)
- Plants/Grass (green)
- Sidewalk (gray)
- Building/Structures (yellow)
Each layer in the 3D structure is a probability or activation map for one class:
- Inside each slice, there is a grid of values (shown as 0s and 1s).
- A “1” means that the pixel is predicted to belong to that class.
- A “0” means it does not belong to that class.
For example:
- In the “Person” layer, the region corresponding to the person contains many 1s (highlighted in red).
- In the “Plants/Grass” layer, only vegetated areas contain 1s (in green).
- Other areas remain 0.
How it works conceptually
- The model processes the input image.
- It produces a stack of feature maps, one per class.
- For each pixel position (x, y):
- The model compares values across all class layers.
- It assigns the pixel to the class with the highest score.
- The diagram shows that semantic segmentation is not just labeling an image directly.
- Internally, the model builds a 3D tensor (height × width × number of classes).
- The final segmentation map is obtained by selecting the most likely class for each pixel.
- Semantic segmentation works at the pixel level.
- The output is represented as multiple class-specific maps.
- These maps form a 3D volume, where each slice corresponds to one object category.
- The final result is obtained by choosing the best class per pixel across all slices.
References:
An overview of semantic image segmentation.
Bonus
Write down your ideas.



 @Yolanda Muriel
@Yolanda Muriel 
