Large-scale video classification with convolutional Neural Networks.
This article is about:
- CNNs class of models for image recognition problems.
- Dataset of millions of YouTube videos belonging to 487 classes.
- Study the connectivity to a CNN in time domain to take advantage to local spatio-temporal information and suggest a multiresolution, to speed up the training.
CNNs can do Image recognition, segmentation, detection and retrieval. The videos are more difficult to collect, annotate and store.
The Network must process not just one image but several frames of video at a time. To solve this issue we have to modify the architecture to contain two separate parts of process: a context stream that learns features of low-resolution frames and a high resolution fovea stream that only operates on the middle portion of the frame.
It can be observed 2–4x increase in run-time performance on the network due to the reduced dimensionality of the input, while networking classification accuracy. The transfer learning problem improves performance (65% up related to 41%).
Video classification involves three stages:
First, local visual features that describe a region of video are extracted either densely or at a sparse set of interest points. Next, the features get combined into a fixed-sized video-level description. One popular approach is to quantize all features with a learned means «dictionary» and accumulate the visual words over the duration of the video into histograms. Lastly, a classifier is trained on the resulting “bag of words” representation to distinguish among different classes of interest.
CNN replace all three stages with a single neural network that is trained end-to-end from raw pixel values to classifier outputs.
Videos vary in temporal extent, and cannot be applied with a single fixed-sized architecture.
Several approaches to fusing information across temporal domain like:
- Single-frame.
- Early fusion.
- Late fusion.
- Fovea and context streams.
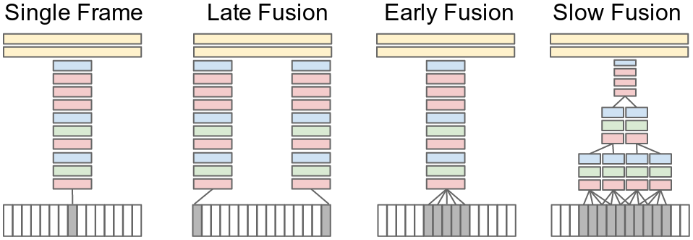
© Image. Large-scale Video Classification with Convolutional Neural Networks
In Multi-resolution CNN architecture, Input frames are fed into two separate streams of processing:
- a context stream that uses low-resolution image;
- a fovea stream (high-resolution).
Both streams have alternating convolution (red), normalization (green) and pooling (blue) layers. Both streams converge to two fully connected layers (yellow).
- Fovea stream
- Context stream
- Fully connected layers
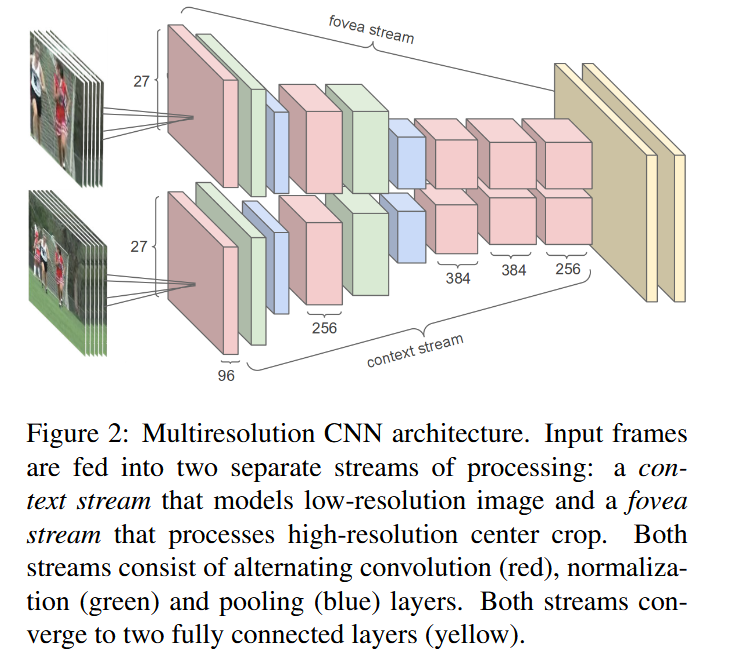
© Image. Large-scale Video Classification with Convolutional Neural Networks
References.
Large-scale Video Classification with Convolutional Neural Networks
Bonus
write down your ideas.


 @Yolanda Muriel
@Yolanda Muriel 
