A gentle horror story about a friendly function that turns fear into probabilities.
On a foggy night, in a valley of numbers, there lived a curve named Sigmoid.
Sigmoid had a special power: whenever a wild number wandered close—maybe −10 (very gloomy) or +10 (super confident)—Sigmoid hugged it and turned it into a calm value between 0 and 1. In other words, any real number went in, and a tidy “likelihood” came out. That’s why scientists use Sigmoid when they want something that looks like a probability.
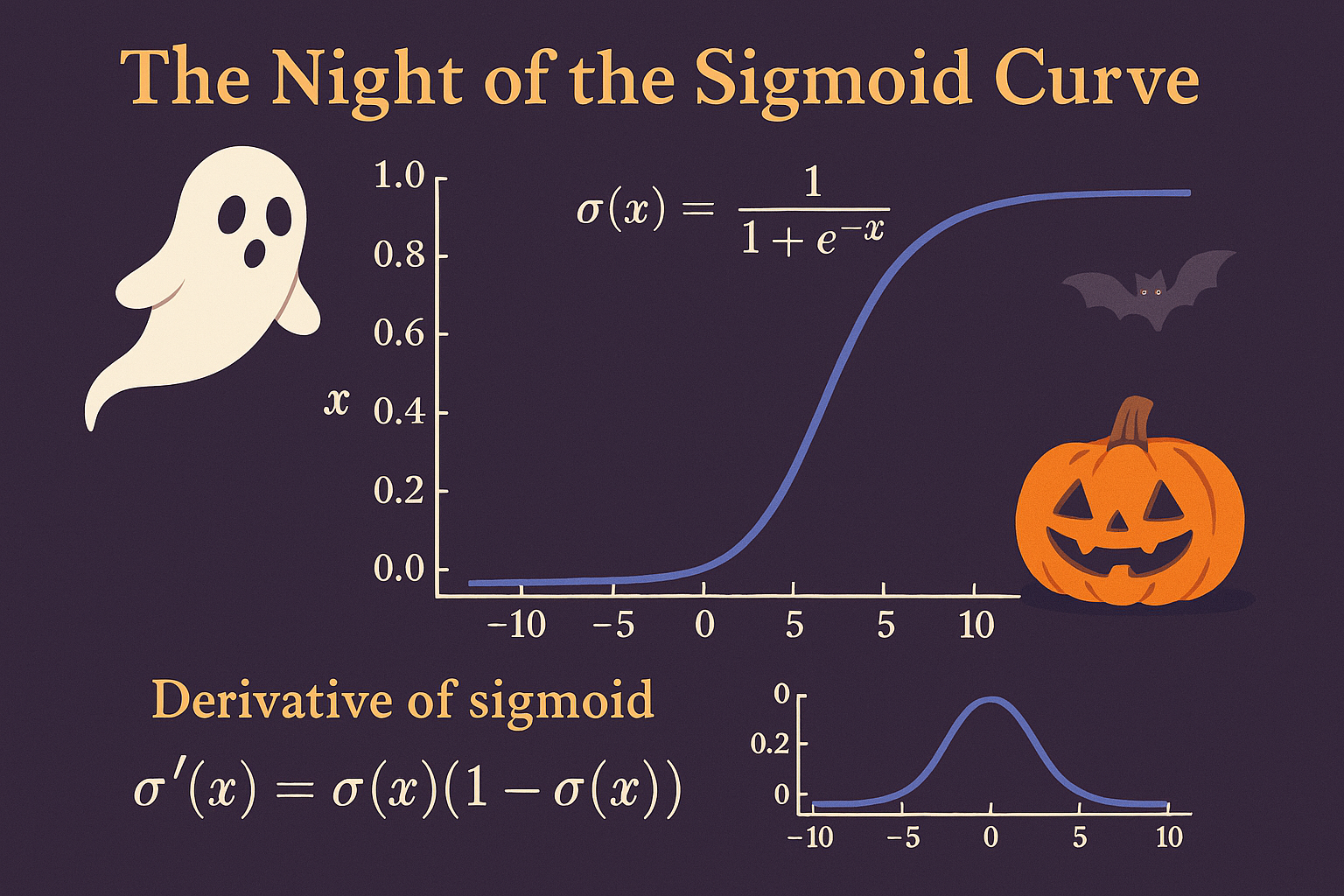
sigma(x) = 1 / (1 + e^(-x))
This is the logistic (sigmoid) function—the same one used in logistic regression. It’s a smooth “S” curve that climbs from 0 to 1.
Chapter 1: The Gate Between Worlds (0 and 1)
In the valley, some creatures were binary: ghost or no ghost, spam or not spam. For such two‑choice stories, Sigmoid guarded the gate. You fed it a number, and Sigmoid returned how likely it was that the answer belonged to Class 1 (for example, “ghost”)—a tidy value in [0, 1]. That’s why Sigmoid is used for binary classification.
But in the forest beyond, there were many monsters—vampire, witch, zombie, mummy—more than two. For those nights, a cousin called Softmax took over: it eats a vector of numbers and returns several probabilities that add up to 1, one for each monster. (Softmax is like a many‑door gate.)
- Sigmoid → one yes/no door (binary).
- Softmax → many doors, probabilities sum to 1 (multiclass)
Chapter 2: Odds, Whispers, and the Secret Name “Logit”
Sigmoid’s magic has an old spell behind it: odds and log‑odds (logit).
If is the chance of “ghost,” the odds are . And the logit is . Sigmoid is actually the inverse of logit, which is why it naturally maps any number back into a probability‑like value between 0 and 1.
odds = p / (1 – p)
logit(p) = log( p / (1 – p) )
sigma(x) = 1 / (1 + e^(-x)) // inverse-logit
Chapter 3: The Shape of a Scream (Why the S‑Curve Feels Right)
Imagine a haunted hallway with a dimmer switch:
- Far left: the lamp is almost off : output near 0
- Far right: the lamp is fully on : output near 1
- In the middle, a tiny nudge changes brightness a lot : the curve is steep
That is exactly how the sigmoid feels. It monotonically increases from 0 to 1 and is smooth everywhere, so it’s comfortable for models that must adjust gently. It’s the go‑to in logistic regression for turning a linear score into a “probability‑like” number.
Chapter 4: The Derivative—Measuring How Fast the Night Changes
One stormy night, we asked: “How fast does Sigmoid change right now if x moves a tiny bit?”
That’s the derivative—a small speedometer for the curve.
Surprisingly, the derivative has a tiny, elegant formula:
sigma'(x) = sigma(x) * (1 – sigma(x))
This matches the spooky intuition:
- Near 0 or 1 (flat parts), the product is small : slope near 0
- Near 0.5 (steepest part), the product is largest (0.25) : fast change
This compact form is exactly what you’ll see in logistic‑style models and neural nets when gradients flow through a sigmoid.
sigma'(x) = e^(-x) / (1 + e^(-x))^2
Epilogue: Why the Villagers Loved Sigmoid
Because Sigmoid tames wild numbers into gentle probabilities, it is perfect for binary classification and for the output of a single neuron that must say “yes/no.” Its derivative is simple and fast, which helps learning algorithms adjust in small, stable steps—no need to fear the dark!
Sources (friendly reading)
- “Sigmoid and SoftMax Functions in 5 minutes” — overview of sigmoid vs softmax, binary vs multiclass, and the logistic link from odds/logit.
 @Yolanda Muriel
@Yolanda Muriel 
