A language model is a model that predicts the next word based on the words it has already seen. Everyday examples include smartphone keyboards that suggest the next word while you type. GPT‑2 does the same thing, but at a much larger scale. It was trained on a huge dataset (WebText, about 40GB of text from the internet), allowing it to generate long, coherent passages of text.

© Image. jalammar.github.io/illustrated-gpt2
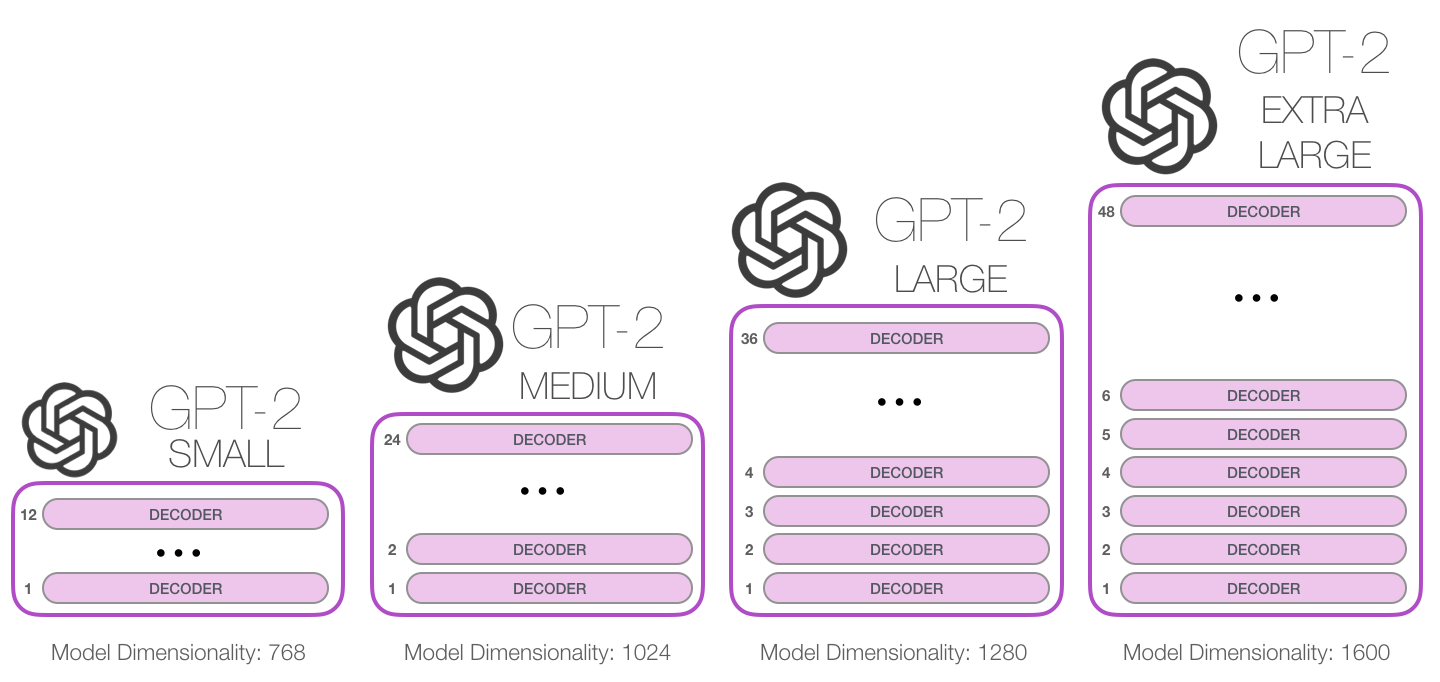
GPT‑2 is based on the transformer architecture, but unlike the original transformer used for translation, it uses only the decoder part. This makes GPT‑2 a decoder‑only transformer.The Illustrated Transformer was the original Transformer model that has an Encoder and a Decoder (Transformer Blocks). That architecture was appropriate because the model tackled Machine Translation.
![]()
© Image. jalammar.github.io/illustrated-gpt2
Instead of reading the full sentence at once, GPT‑2 generates text one token at a time, always using previous tokens as context. This process is called auto‑regression (The new sequence of tokens produced are added to the sequence of inputs).
One important comparison is between GPT‑2 and BERT. GPT‑2 reads text strictly from left to right and never looks at future words. BERT, by contrast, sees words on both sides of a token, which helps with understanding but prevents natural step‑by‑step text generation. GPT‑2’s left‑to‑right design makes it better suited for writing text.
![]()
© Image. jalammar.github.io/illustrated-gpt2
GPT-2 like traditional language models outputs one token at time.
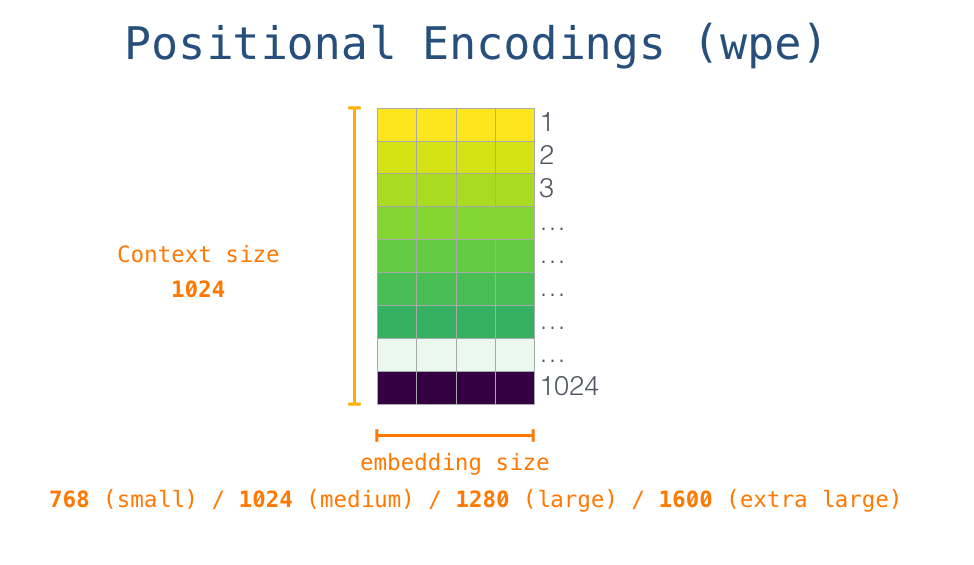
Inside GPT‑2, text is first converted into tokens and then into embedding vectors, which capture meaning numerically (embedding matrix). Positional encodings are added so the model knows the order of words. These vectors pass through a stack of identical decoder blocks.
The detail of the process is that the model looks the embedding of the start token in the embedding matrix, and then add up the positional encoding vector for position #1… (a signal that indicates the order of the words in the sequence of the transformer blocks).
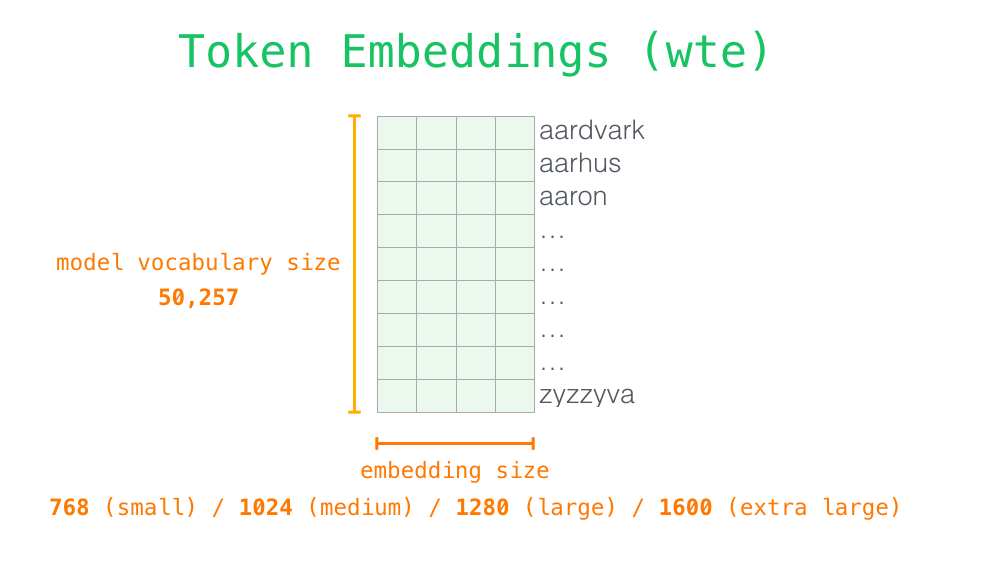
Each row is a word embedding: a list of numbers representing the word.
© Image. jalammar.github.io/illustrated-gpt2
The first block of GPT-2 can process the token by first passing it through Self-attention process, then passing it through Neural Network Layers.
So each block contains two key parts:
- Masked self‑attention, which lets a word focus only on earlier words (never future ones).
- A feed‑forward neural network, which further transforms the information.
![]()
© Image. jalammar.github.io/illustrated-gpt2
Masked Self‑attention is crucial because language depends heavily on context. For example, words like “it” or “such orders” only make sense if the model knows what they refer to earlier in the sentence. Self‑attention solves this by letting each word weigh the importance of previous words when building its representation.
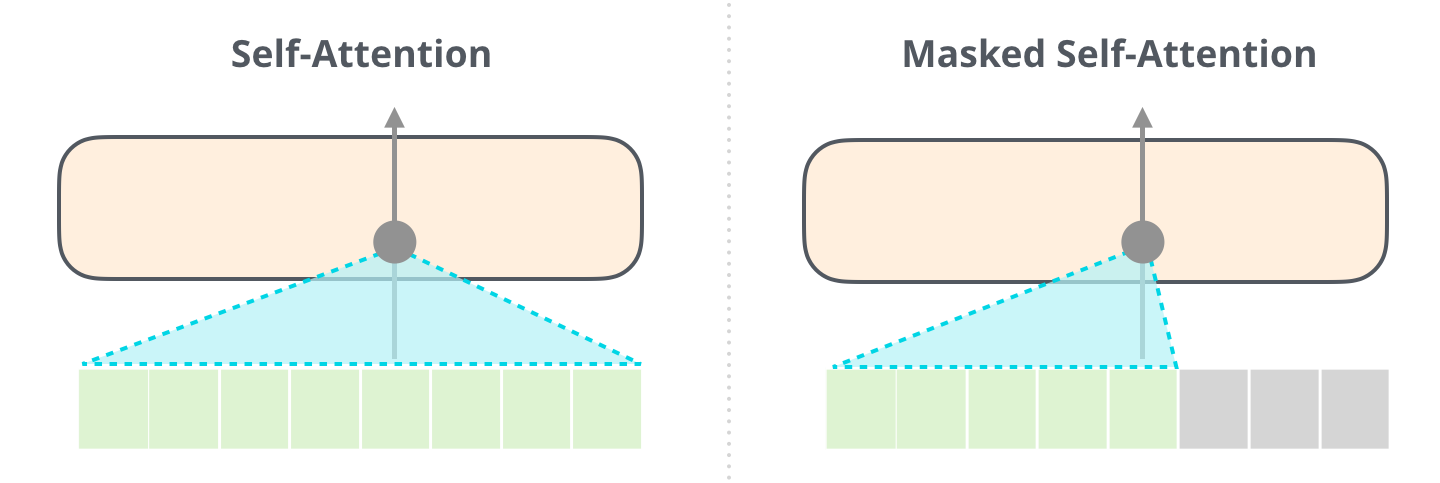
A normal self-attention block allows a position to read tokens to its right. Masked self-attention prevents that.
© Image. jalammar.github.io/illustrated-gpt2
Once the first Transformer block processes the token, it sends the resulting vector to be processed by the next block. The process is identical in each block, but each block has its own weights in both Self-attention and the Neural Network sub-layers.
After the final block, GPT‑2 converts the resulting vector into scores for every word in its vocabulary. The model then chooses the next word, either by selecting the most likely one or by sampling from the top candidates to produce more varied text.
GPT‑2 is essentially a very powerful next‑word prediction machine, and that its impressive results come from scale: large datasets, many layers, and efficient use of self‑attention.
The self-attention process has three vectors:
- Query. Is the representation of the current word.
- Key. Is the label that has every word in the segment.
- Value. Is the actual representation of the word, once scored how relevant is the word.
GPT-2 uses Byte Pair Encoding to create the tokens in its vocabulary, that means the tokens are part of words.
References:
The Illustrated GPT-2 (Visualizing Transformer Language Models) by Jay Alammar.
 @Yolanda Muriel
@Yolanda Muriel 
