A Count Vectorizer is a way for a computer to understand a sentence by counting words instead of looking at their order.
First, it creates a list of all possible words (this is called the vocabulary), and each word gets a position in a vector. Then, for any sentence, the computer just counts how many times each word appears and puts that number in the correct position.
For example, imagine the vocabulary is [«apple», «banana», «orange»]. If the sentence is “apple banana apple”, the vector would be [2, 1, 0] because “apple” appears twice, “banana” once, and “orange” not at all. In this way, the whole sentence is summarized into a single vector that shows word frequency, even though it loses the order of the words.
When we use a Count Vectorizer, every sentence becomes a vector with the same length, and this length depends on how many different words exist in the vocabulary. This makes it easy for a computer to compare sentences, because they all have the same format. However, there is an important limitation: the model completely ignores the order of the words. That means the sentence “apple banana” and “banana apple” would have exactly the same vector, even though they might mean different things. So, while count vectors are good at showing how often words appear, they lose the context and structure of the original sentence.
Count vectors are often used for things like spam email detection. The idea is simple: the model looks at how often certain words appear in spam emails versus normal emails. For example, words like “money” or “win” might appear more often in spam. During training, the model learns which words are more “spam-like” and which are not.
To decide if a new email is spam, the model uses something called Bayes’ theorem, which is just a way to calculate probability using what we already know. In simple terms, it answers this question: “Given the words in this email, how likely is it that the email is spam?” It does this by combining two things: how common those words are in spam emails, and how common spam emails are in general.
To make things easier, the model assumes that all words are independent (this is why it’s called Naive Bayes). That means it treats each word separately and multiplies their probabilities together to get the final result.
However, there is a problem. If the model sees words it has never seen before, it just ignores them. Spammers can trick the system by slightly changing words (like writing “m0ney” instead of “money”). Humans can still understand the message, but the model may fail and think the email is not spam because it doesn’t recognize those modified words.
Feature hashing
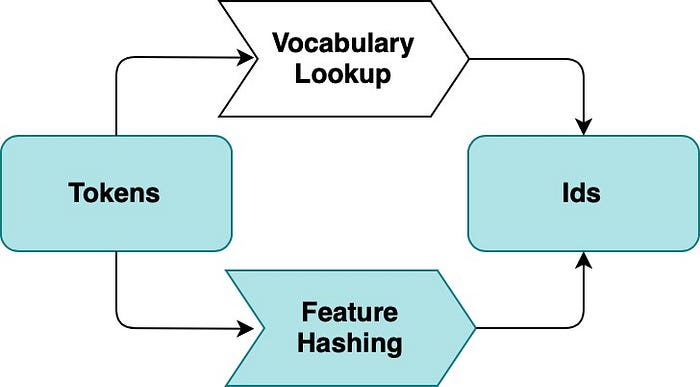
When models learn from a lot of text, they usually build a huge list of all words (called a vocabulary). This list can become very large and use a lot of memory, which can slow things down. To solve this, we can use something called the hashing trick. Instead of storing every word in a list, we use a function that converts any word into a number. This number is then used as its position in a vector.
© Image. https://medium.com/data-science/an-overview-for-text-representations-in-nlp
The good thing is that this works for any word, even if the model has never seen it before. For example, in spam detection, if someone writes “m0ney” instead of “money”, the model will still process it instead of ignoring it. This makes the system more robust because no words are discarded.
However, there is a small downside. This method is one-way, meaning we cannot go back from the number to the original word. Also, sometimes two different words might accidentally get the same number (this is called a collision), but if the vector is large enough, this rarely causes problems.
Tf-idf term weighting
TF-IDF is a way to improve count vectors by giving more importance to meaningful words and less importance to very common ones. In normal count vectors, words like “the”, “and”, or “is” can appear many times, but they don’t really help us understand the meaning of a sentence. TF-IDF fixes this by adjusting the weight of each word.
It works in two parts. First, term frequency (TF) counts how often a word appears in a sentence. Then, inverse document frequency (IDF) reduces the importance of words that appear in many different sentences. The idea is simple: if a word appears everywhere, it is probably not very informative. But if a word appears only in a few sentences, it is more special and meaningful.
For example, imagine many sentences contain the word “the”, but only a few contain the word “neural”. TF-IDF will give a low weight to “the” and a higher weight to “neural”. This helps the model focus more on important words and better understand the context of the text.
References:
Article: An Overview for Text Representations in NLP. Author: jiawei hu. Published on Medium.
Generalized Language Models by Lilian Weng.
 @Yolanda Muriel
@Yolanda Muriel 
