This article explains a naive approach to semantic segmentation using a sliding window classifier and a CNN (Convolutional Neural Network). Instead of classifying the whole image at once, the method classifies one pixel at a time by looking at a small region (patch) around that pixel.
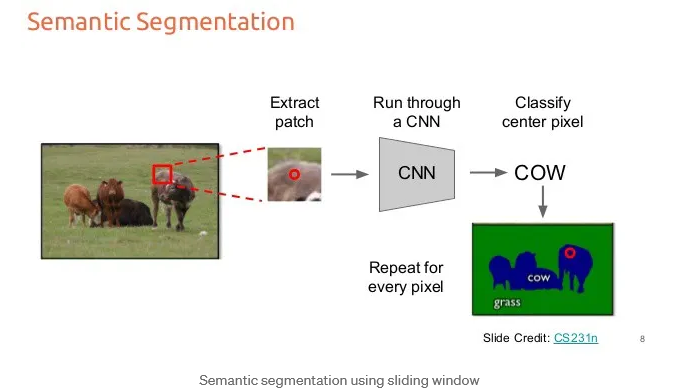
Input image
- On the left, there is an image of animals (cows) standing on grass.
- A small red square highlights a local region of the image.
Extract a patch
- A small patch (sub-image) is cropped around a specific pixel (the red dot).
- This patch provides local context (nearby pixels) to help classification.
Run through a CNN
- The extracted patch is passed into a CNN model.
- The CNN analyzes the patch and predicts what object is in the center.
Classify the center pixel
- The model outputs a label (e.g., “COW”).
- This label is assigned only to the center pixel of the patch.
Repeat for every pixel
- This process is repeated pixel by pixel across the entire image.
- Eventually, every pixel gets a label.
Final segmentation map
On the bottom right, the result shows:
- Blue regions are cow.
- Green regions are grass.
- Each pixel in the image has been classified.
Why this is called “naive”
This approach works, but it has important drawbacks:
- Very slow : The CNN runs once per pixel (extremely expensive).
- Redundant computation : Overlapping patches repeat the same calculations.
- Inefficient compared to modern methods (like fully convolutional networks).

©image.Ravindra Parmar
Fully convolutional layer for semantic segmentation
The image demonstrates that:
- Semantic segmentation can be done by classifying each pixel using local patches.
- However, this sliding window method is inefficient, which is why better techniques are used today.
References:
Detection and Segmentation through ConvNets
Sliding Windows for Object Detection with Python and OpenCV
 @Yolanda Muriel
@Yolanda Muriel 
