Instead of directly asking humans for preferences, model their preferences as a separate (NLP) problem. This means: Humans label or rank a limited number of outputs, a reward model learns to imitate human judgments, the language model is optimized against the reward model, not directly against humans.
This idea is inspired by earlier work (e.g., Knox and Stone, 2009) on learning from human preferences.
The Example
A single prompt (x) with two possible model outputs:
Prompt:
Something related to an earthquake in San Francisco.
Output y₁:
“An earthquake hit San Francisco. There was minor property damage, but no injuries.”
Output y₂:
“The Bay Area has good weather but is prone to earthquakes and wildfires.”
Humans clearly prefer y₁, because: It directly answers the prompt, it is specific and factual and it is relevant to the event described.
Human Reward Signal
Humans assign preference-based scores:
- R(x, y₁) = 8.0
- R(x, y₂) = 1.2
Important points: These numbers do not come from humans directly during training, humans typically rank outputs, not assign exact numbers, and the numeric reward is produced by a trained reward model.
The Reward Model
Train an RMφ(x, y) to predict human reward from an annotated dataset, then optimize for RMφ instead.
What RMφ means:
- RM = Reward Model
- φ (phi) = model parameters
- Inputs: prompt x and output y
- Output: predicted human preference score
This reward model is a neural network trained on human-labeled comparisons.
PPO
Once we have a reward model, we want to update the language model so that: It produces outputs with higher predicted reward, and it does not change too abruptly, which could harm language quality. This is where Proximal Policy Optimization (PPO) comes in.
Proximal Policy Optimization (PPO)
PPO is a reinforcement learning algorithm designed to: Optimize a policy (the language model), while keeping updates small and stable. Key properties: Prevents the model from exploiting reward model weaknesses, maintains fluency and coherence, and balances exploration and safety. In simple terms: PPO nudges the model toward better answers without breaking it.
How PPO Works
- The model generates several candidate answers.
- The reward model scores them.
- PPO adjusts the model’s parameters to:
- Increase probability of high-reward outputs (like y₁).
- Decrease probability of low-reward outputs (like y₂).
- Constraints ensure the new model stays close to the previous version.
This “proximal” constraint is the reason for the algorithm’s name.
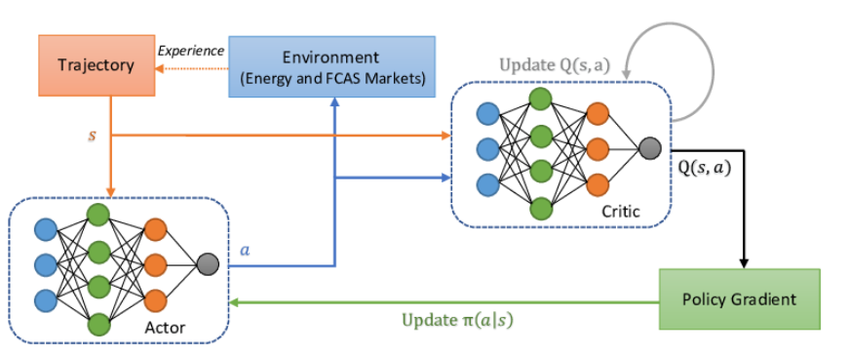
© Image. Proximal Policy Optimization (PPO) architecture. Financial News-Driven LLM Reinforcement Learning for Portfolio Management
PPO Is Especially Important for Language Models
Without PPO: The model may “game” the reward model, Outputs may become repetitive, exaggerated, or unsafe, and Language quality can degrade. With PPO: Training remains stable, Responses improve gradually and Human alignment is preserved. This is why PPO is the standard optimization algorithm for RLHF in large language models.
In summary:
- Human feedback is expensive and limited.
- A reward model is trained to approximate human preferences.
- The language model is optimized against this reward model.
- PPO is used to make stable, controlled improvements.
- The example shows how better, more relevant answers receive higher reward.
- This process is central to how ChatGPT learns to produce helpful responses.
Bonus
Write down your ideas on paper.


 @Yolanda Muriel
@Yolanda Muriel 
