Knowledge Graphs (KGs) are made up of subject-predicate-object triples and have become an essential structure for retrieving information. Most real-world KGs, such as Wikidata, DBpedia, and YAGO, are still incomplete because many relationships between entities are missing.
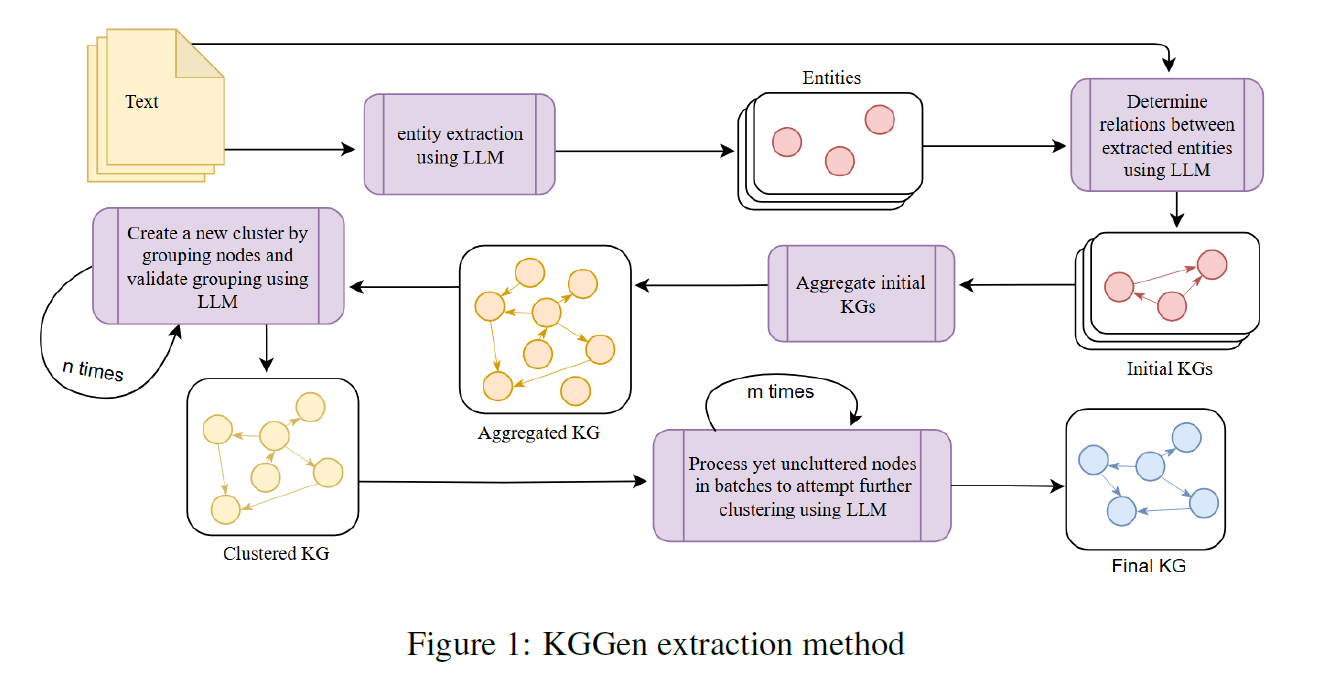
To address this issue, we introduce KGGen, a text-to-knowledge-graph generator that uses language models (LMs) together with an entity and relation resolution algorithm to produce dense, high-quality KGs from text. First, KGGen employs an LM-based extractor to analyze unstructured text and generate subject-predicate-object triples that represent entities and relationships; once the triples are extracted, it applies a new iterative clustering algorithm to improve the initial graph. Inspired by crowdsourcing techniques for entity resolution, KGGen detects nodes that correspond to the same underlying entity and merges edges with equivalent meanings.
The emerging field of extracting knowledge graphs from plain text still lacks benchmarks capable of evaluating the accuracy of KG generation from text. To address this limitation, we introduce two new benchmarks: the first evaluates information preservation from short texts, while the second, based on WikiQA, measures knowledge retrieval abilities for graphs generated from web-based databases containing millions of tokens.
On these benchmarks, KGGen achieves performance comparable to GraphRAG. However, KGGen demonstrates much stronger scalability in terms of information compression and graph sparsity as the size of the plain-text database grows.
Existing methods: two widely used approaches for extracting KGs from plain text are:
Open Information Extraction (OpenIE), implemented by Stanford CoreNLP.
GraphRAG, created by Microsoft in 2024, combines graph-based knowledge retrieval with language models (LMs).
Entity and Relation Extraction
The first stage receives unstructured text as input and generates an initial knowledge graph through extracted triples. We use Google’s Gemini 2.0 Flash as the language model to produce structured outputs through DSPy signatures. The first step processes the source text and extracts a list of entities. Using both the source text and the entity list, the second step generates a list of subject-predicate-object relations.
Aggregation
After extracting triples from every source text, all unique entities and edges from the source graphs are collected and merged into a single graph. Every entity and edge is normalized into lowercase format only. The aggregation stage minimizes redundancy within the KG. This stage does not require an LLM.
Entity and Edge Resolution
After extraction and aggregation, the resulting raw graph usually contains duplicate or synonymous entities together with redundant edges. The resolution stage merges nodes and edges that correspond to the same real-world entity or concept. This process applies a two-stage strategy that combines embedding-based clustering with LLM-based deduplication to efficiently manage large knowledge graphs.
First, all graph items are grouped into clusters. Semantic embeddings for every item are generated using S-BERT, and k-means clustering is applied to create clusters of 128 items.
- For every item within a cluster, the system retrieves the top-k most semantically similar items, where k=16, using a combination of BM25 retrieval and semantic embeddings.
- The LLM is then prompted to identify exact duplicates within this set while considering differences in tense, plurality, capitalization, abbreviations, and shorthand expressions.
- For every duplicate set, the LLM chooses a canonical representative that best reflects the shared meaning, similar to the aliases used in Wikidata. Cluster mappings keep track of which entities belong to each alias.
- The item and all its duplicates are removed from the cluster, and steps 1–3 are repeated until no items remain inside the cluster.
© Image. Belinda Mo, Kyssen Yu, Joshua Kazdan, Joan Cabezas, Proud Mpala, Lisa Yu, Chris Cundy, Charilaos Kanatsoulis, Sanmi Koyejo
References:
KGGen: Extracting Knowledge Graphs from Plain Text with Language Models
Bonus
Write down your ideas.



 @Yolanda Muriel
@Yolanda Muriel 
