Retrieval‑Augmented Generation (RAG) is an architecture that combines: Information retrieval (searching relevant documents), and Text generation (using a Large Language Model).
Instead of relying only on what the model learned during training, RAG allows the model to: Look up external, up‑to‑date, or private knowledge, and Use that retrieved information as context when generating an answer. This drastically improves accuracy, grounding, and trustworthiness.
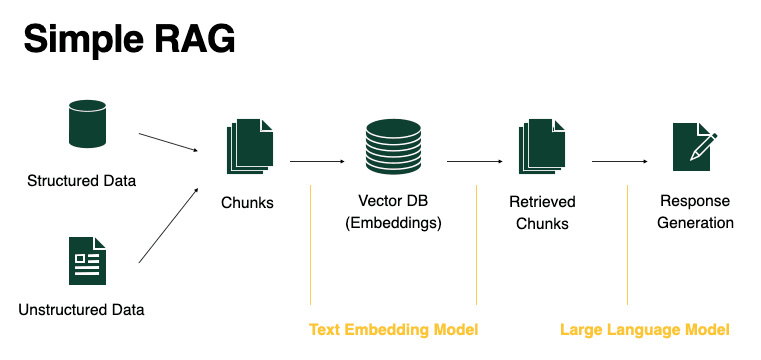
Overview of the Main Parts
There are four core components of a RAG system:
- Query
- Embedding Model
- Vector Database
- LLM
These components form a pipeline from user input to final answer.
Query: Input provided by the user. The query is the user’s question or request.
- Example:
- “What are the safety requirements for emergency lighting systems?”
- “Summarize the company’s data retention policy.”
The query is the starting point of the RAG pipeline, and used both for retrieval and for final answer generation.
Embedding Model
Model used to compute vector representations of our queries and context information. Embeddings are numerical vector representations of text. Texts with similar meaning have vectors that are close in vector space.
Role of the embedding model: Converts the user query into a vector, converts documents or text chunks into vectors and enables semantic (meaning‑based) search instead of keyword search.
Importance of chunking
Finding the right way to split our data (chunks) is important to obtain good results.
Why chunking matters: Large documents must be split into smaller pieces, Chunks that are too large: May exceed context limits and Reduce retrieval precision, and Chunks that are too small: May lose meaning or context.
Good chunking leads to: Better retrieval relevance and more grounded and accurate answers.
Vector Database
Database that stores all the vector representations and allows an efficient comparison with our queries. It Stores vectors for all document chunks, Supports fast similarity search (e.g., cosine similarity) and Retrieves the top‑K most relevant chunks for a given query.
Why a vector database is needed: Comparing embeddings directly is computationally expensive and Vector databases are optimized for: Speed, Scalability and Large collections of embeddings.
Examples (conceptually):
- FAISS
- Pinecone
- Weaviate
- Qdrant
LLM (Large Language Model)
Model that generates an answer based on the information provided by the query and the context information.
Role of the LLM:
- Receives The original query and The retrieved context from the vector database. Generates a final answer using this combined input.
Key advantage:
- The LLM is no longer guessing.
- It is responding based on explicit retrieved evidence.
This reduces: Hallucinations, Out‑of‑date answers and Unsupported claims.
How the Full RAG Pipeline Works
- User submits a query
- The embedding model converts the query into a vector
- The vector database retrieves relevant document chunks
- The LLM receives:
- The query
- The retrieved chunks as context
- The LLM generates a grounded, context‑aware answer
Why RAG Is So Important
RAG is critical for real‑world applications because it allows:
- Use of private or enterprise data.
- Answers based on current information.
- Better factual accuracy.
- Clear traceability to source documents.
This is why RAG is widely used in:
- Enterprise copilots.
- Knowledge bases.
- Customer support systems.
- Legal and compliance tools.
- Technical documentation assistants.
In short:
- Query: what the user asks.
- Embedding model: converts text into vectors.
- Vector database: finds relevant information efficiently.
- LLM: generates the final answer using retrieved context.
Together, these parts transform a language model from a static text generator into a knowledge‑grounded assistant.
© Image. Chaoyu Yang
Bonus
Write down your ideas.

Bonus 2
References:
 @Yolanda Muriel
@Yolanda Muriel 
