Word embeddings are a more advanced way to represent words compared to count vectors. Instead of just counting words, each word is turned into a vector of numbers that captures its meaning. These numbers represent different hidden features (like gender, age, or other abstract properties), but we don’t define them manually—the model learns them automatically during training. This means similar words end up with similar vectors. For example, words like “king” and “queen” will be close to each other because they share similar meanings.
A very interesting property of embeddings is that they can capture relationships between words. For instance, the difference between “king” and “queen” is similar to the difference between “man” and “woman”. This is why operations like: «king» – «queen» + «woman» – «man» make sense mathematically.
In short, embeddings don’t just represent words—they capture meaning and relationships between them, which helps models understand language much better.
Word embeddings are actually long vectors with many numbers (many dimensions), so they are hard to visualize directly. To make them easier to understand, we can use a technique called t-SNE, which reduces these high-dimensional vectors into just 2 dimensions so we can plot them on a graph.
When we do this, something interesting happens: words with similar meanings appear close to each other on the graph, while very different words appear far apart. For example, words like “king”, “queen”, and “prince” would be grouped together, while a word like “car” would be far away. This shows that embeddings are not just random numbers—they actually capture the meaning of words in a way that can be visualized.
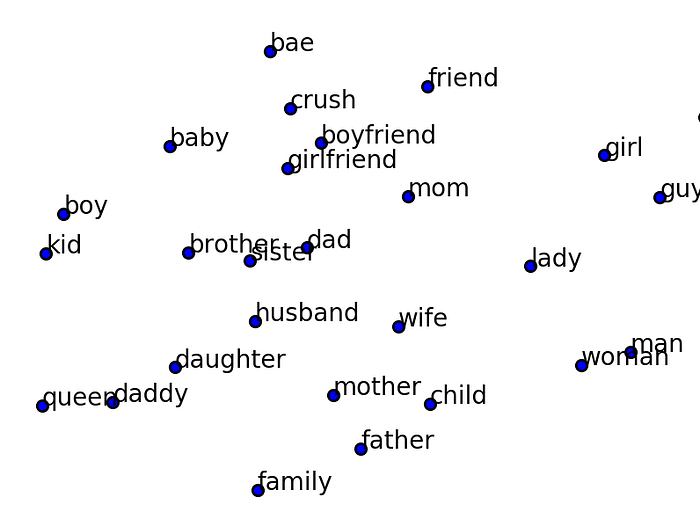
© Image. https://medium.com/data-science/an-overview-for-text-representations-in-nlp
Training Word Embeddings
Word embeddings can be trained like part of a neural network or learned separately and reused later. One popular method is Word2Vec, which learns word meanings by looking at how words appear near each other in sentences.
The basic idea is this: words that appear in similar contexts tend to have similar meanings. So during training, the model looks at a sentence, picks one word (called the target), and looks at the nearby words (called the context). For example, in the sentence “Learning Chinese is hard but also fun”, if the target word is “is”, the context could be words like “Learning”, “Chinese”, “hard”, and “but”.
There are two main ways to train this:
- In CBOW (Continuous Bag of Words), the model looks at the context words and tries to guess the target word.
- In Skip-gram, the model does the opposite: it looks at the target word and tries to predict the surrounding context words.
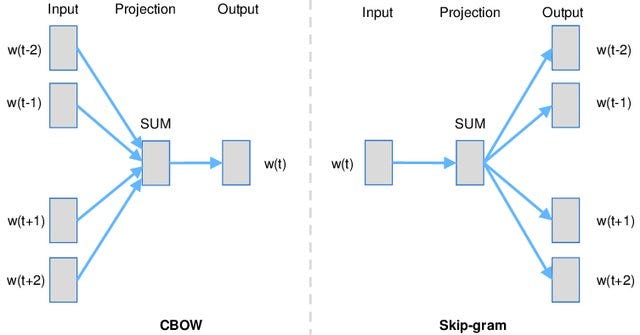
© Image. https://medium.com/data-science/an-overview-for-text-representations-in-nlp
Even though this may sound like a simple guessing task, the real goal is not the prediction itself, but learning good word representations. By doing this many times on large text data, the model learns embeddings where words with similar meanings end up having similar vectors.
Contextualized Word Embedding
Modern NLP models follow a very powerful idea: first learn general language, then specialize for a task. This is called pre-training + fine-tuning. First, a model is trained on a huge amount of text to understand language (grammar, meaning, context). Then, the same model is slightly adjusted (fine-tuned) to do a specific task like translation, classification, or question answering.
A classic example is an encoder-decoder model used in translation. The encoder reads a sentence and turns it into a meaningful representation (embedding), and the decoder uses that to generate the translated sentence. After training, the encoder becomes very good at understanding language, so we can reuse it for other tasks.
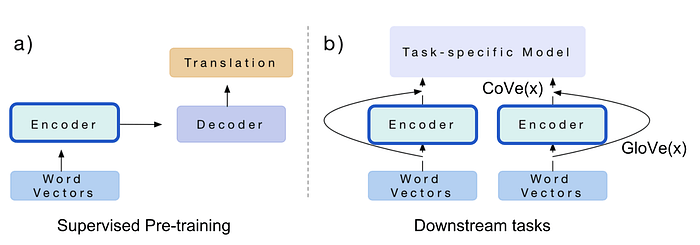
© Image. https://medium.com/data-science/an-overview-for-text-representations-in-nlp
Early approaches like ELMo used LSTMs and learned word meaning by predicting words in a sentence. It looks both left and right, so it captures context well, but it still needs a separate model for each task.
Later, models like GPT improved this by using Transformers and could be directly adapted to many tasks with small changes. However, GPT mainly looks at words from left to right. GPT is trained only to predict the future.
Then came BERT, which was a big breakthrough. BERT looks at both left and right context at the same time, giving it a deeper understanding of language. It is trained with tasks like:
- guessing missing words in a sentence. Mask language Model.
- understanding if two sentences are related. Next sentence prediction.
After pre-training, BERT can be easily fine-tuned for many tasks by adding a small extra layer.
In short, the key idea is: instead of training a model from zero every time, we train a big model once on lots of data, and then reuse it for many different tasks with small adjustments.
References:
Article: An Overview for Text Representations in NLP. Author: jiawei hu. Published on Medium.
Generalized Language Models by Lilian Weng.
 @Yolanda Muriel
@Yolanda Muriel 
