Regular Fine‑Tuning
In standard fine‑tuning: The model starts with pretrained weights W, during training, the model learns a full weight update ΔW and the effective weight matrix becomes: Wnew=W+ΔW.
- W (pretrained weights): large matrix of dimension d×d.
- ΔW (weight update): same size as W.
- Both W and ΔW contribute directly to the outputs.
- All (or most) parameters are updated during training.
Consequences
High flexibility, very memory‑intensive, slow to train and requires storing a full copy of the model per task. For large language models, ΔW can contain billions of parameters, making regular fine‑tuning expensive and impractical in many settings.
LoRA
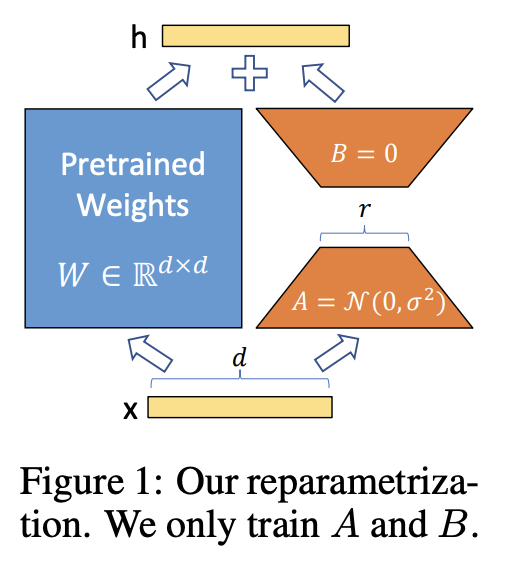
LoRA (Low‑Rank Adaptation) is based on a key observation: The task‑specific weight update ΔW often lies in a low‑dimensional subspace. Instead of learning the full ΔW, LoRA approximates it using two much smaller matrices.
Weight Update in LoRA
Instead of learning ΔW directly, LoRA parameterizes it as:
ΔW≈BA
Where:
- A is a matrix of shape r×d
- B is a matrix of shape d×r
- r is the rank, and r≪d
The pretrained weights W remain frozen.
Effective weight during inference
Weffective=W+BA
This is functionally similar to regular fine‑tuning, but vastly cheaper.
Pretrained weights 
- Large matrix.
- Frozen during LoRA training.
- Represents general language knowledge.
LoRA matrices (A and B)
- Small, trainable matrices.
- Capture task‑specific adaptation.
- Together approximate the full update ΔW.
Rank r
- Labeled.
- A hyperparameter.
- Controls the trade‑off between:
- Expressiveness.
- Parameter efficiency.
Typical values: 4, 8, 16, 32.ç
© Image. Shaoni Mukherjee
Why LoRA Is So Much More Efficient
Parameter count comparison
Let original weight size be d×d:
- Regular fine‑tuning:
d2 trainable parameters
- LoRA fine‑tuning:
2dr trainable parameters
Since r≪d, LoRA reduces parameters by orders of magnitude.
Practical Benefits of LoRA
Massive memory savings, Faster training, Multiple adapters per base model, Easy to switch or combine task behaviors and Ideal for large LLMs.
This is why LoRA is widely used for:
- Domain adaptation.
- Instruction tuning.
- Personalization.
- On‑device or low‑resource training.
Comparison
| Aspect | Regular Fine‑Tuning | LoRA |
|---|---|---|
| Pretrained weights | Updated | Frozen |
| Trainable parameters | Full ΔW | Low‑rank A and B |
| Memory usage | Very high | Very low |
| Training stability | Medium | High |
| Task modularity | Low | High |
| Deployment cost | High | Low |
The difference is:
- Regular Fine-Tuning
The model rewrites its knowledge for each new task. - LoRA
The model keeps its original knowledge and learns a small adjustment layer that nudges behavior in the right direction.
You can think of LoRA as:
“Adding a small, task‑specific steering mechanism rather than rebuilding the entire engine.”
In short:
- Regular fine‑tuning updates all model weights that is expensive.
- LoRA freezes pretrained weights and learns a low‑rank update.
- ΔW is approximated as B × A.
- The rank r determines efficiency vs expressiveness.
- LoRA enables scalable, modular, and cost‑effective fine‑tuning.
This is why LoRA has become a standard technique for adapting large language models.
References:
LoRA: Low-Rank Adaptation of Large Language Models Explained
 @Yolanda Muriel
@Yolanda Muriel 
