Understanding and modeling 3D data has become a central challenge in computer vision and machine learning. Unlike traditional 2D images, 3D representations, such as point clouds, voxel grids, and graphs, introduce unique structural and geometric complexities. A variety of deep learning architectures have been developed to address these challenges, each targeting specific properties of 3D data. This article explores key ideas behind PointNet, Graph Neural Networks (GNNs), Multi-view CNNs, and the limits of the pinhole camera model, highlighting how they collectively contribute to modern 3D understanding.
The Challenge of 3D Data: Beyond Regular Grids
Traditional deep learning models, especially Convolutional Neural Networks (CNNs), are optimized for regularly structured data, such as images organized in pixels. However, many 3D representations are irregular and unordered, particularly point clouds. This creates challenges because neural networks are typically sensitive to input order and structure.
For example: A voxel grid is structured (like a 3D image), making it suitable for 3D CNNs, a point cloud is an unordered set of coordinates, lacking inherent structure, and a graph representation models relationships explicitly through nodes and edges. Each of these formats requires a different approach to processing and learning meaningful features.
PointNet: Learning from Unordered Point Sets
PointNet was a breakthrough architecture designed specifically for point clouds. Its key innovation is addressing the unordered nature of point sets. Since the order of points should not affect the model’s output, PointNet uses symmetric functions, such as max pooling, to ensure permutation invariance.
Key Components of PointNet
- Shared MLP (Multi-Layer Perceptron): Processes each point independently.
- Symmetric aggregation (max pooling): Combines features from all points into a global descriptor.
- T-Net (Transformation Network): Learns to align input data or feature spaces into a canonical form, improving robustness to geometric transformations like rotation and scaling.
The T-Net plays a crucial role by predicting a transformation matrix that normalizes the data, enabling the network to focus on shape rather than orientation.
Graph Neural Networks: Learning from Local Structure
While PointNet treats points independently before aggregation, Graph Neural Networks (GNNs) explicitly model relationships between points. In 3D data, this often means constructing a graph where each point is connected to its neighbors.
The core mechanism of GNNs is message passing, where:
- Each node collects information from its neighbors.
- Features are aggregated (e.g., mean, sum, or max).
- The node updates its representation based on this local context.
This allows GNNs to capture local geometric structures, making them especially powerful for tasks like surface reconstruction, segmentation, and classification.
Importantly, GNNs are not designed for regular voxel grids, but rather for irregular, non-Euclidean data, where relationships are flexible and not tied to a fixed grid.
Multi-view CNNs: Bridging 2D and 3D
Another approach to 3D understanding is to convert 3D data into multiple 2D images. This is the idea behind Multi-view CNNs, where a 3D object is rendered from different viewpoints.
Each view is processed by a CNN, and the resulting features are combined through a process called view pooling.
Purpose of View Pooling
The role of view pooling is to:
- Aggregate features from all 2D views.
- Produce a single, comprehensive descriptor of the 3D object.
- Ensure that information from multiple perspectives is captured.
Typically, operations like max pooling are used to retain the most informative features across views.
This approach leverages the strength of 2D CNNs while overcoming their limitation of not directly handling 3D data.
The Pinhole Camera Model: Limits of 2D Observations
At the heart of many vision systems is the pinhole camera model, which describes how 3D points are projected onto a 2D image plane. However, this projection is inherently lossy.
Why 3D Cannot Be Fully Recovered from a Single Image
- Depth information is collapsed during projection.
- Multiple 3D points can map to the same 2D location.
- The transformation is not invertible.
As a result, a single 2D image is insufficient to fully reconstruct a 3D scene. Recovering 3D structure requires additional data, such as:
- Multiple views (stereo vision or Structure from Motion)
- Depth sensors (e.g., LiDAR, RGB-D cameras)
- Prior knowledge or learned constraints
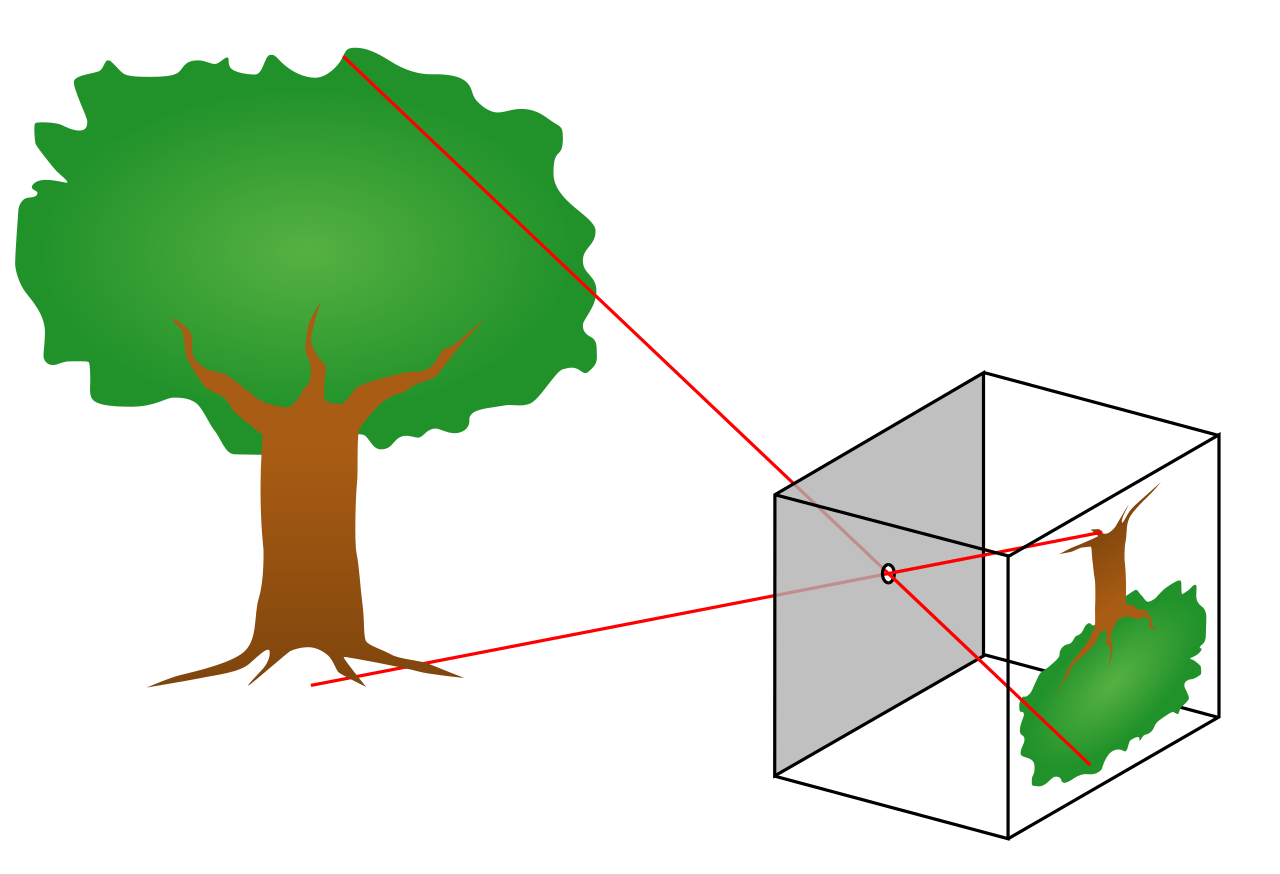

© Image. https://en.wikipedia.org/wiki/Pinhole_camera_model
A diagram of a pinhole camera.The geometry of a pinhole camera. Note: the x1x2x3 coordinate system in the figure is left-handed, that is the direction of the OZ axis is in reverse to the system the reader may be used to.
Conclusion
Modern 3D deep learning methods are shaped by the fundamental properties of 3D data:
- PointNet solves the challenge of unordered point sets using symmetric functions and alignment networks (T-Net).
- Graph Neural Networks model local relationships through message passing, enabling context-aware feature learning.
- Multi-view CNNs leverage multiple 2D projections and view pooling to build robust 3D descriptors.
- The pinhole camera model highlights the inherent limitations of single-view perception, motivating the need for richer data representations.
Together, these approaches illustrate the diversity of techniques required to effectively understand and process 3D information in real-world applications, from autonomous driving to augmented reality and robotics.
Bonus
Write down your ideas.



 @Yolanda Muriel
@Yolanda Muriel 
